2025
A.I.R.: Adaptive, Iterative, and Reasoning-based Frame Selection for Video Question Answering
Yuanhao Zou*, Shengji Jin*, Andong Deng, Youpeng Zhao, Jun Wang, Chen Chen (* equal contribution)
Submitted to International Conference on Learning Representations (ICLR) 2026
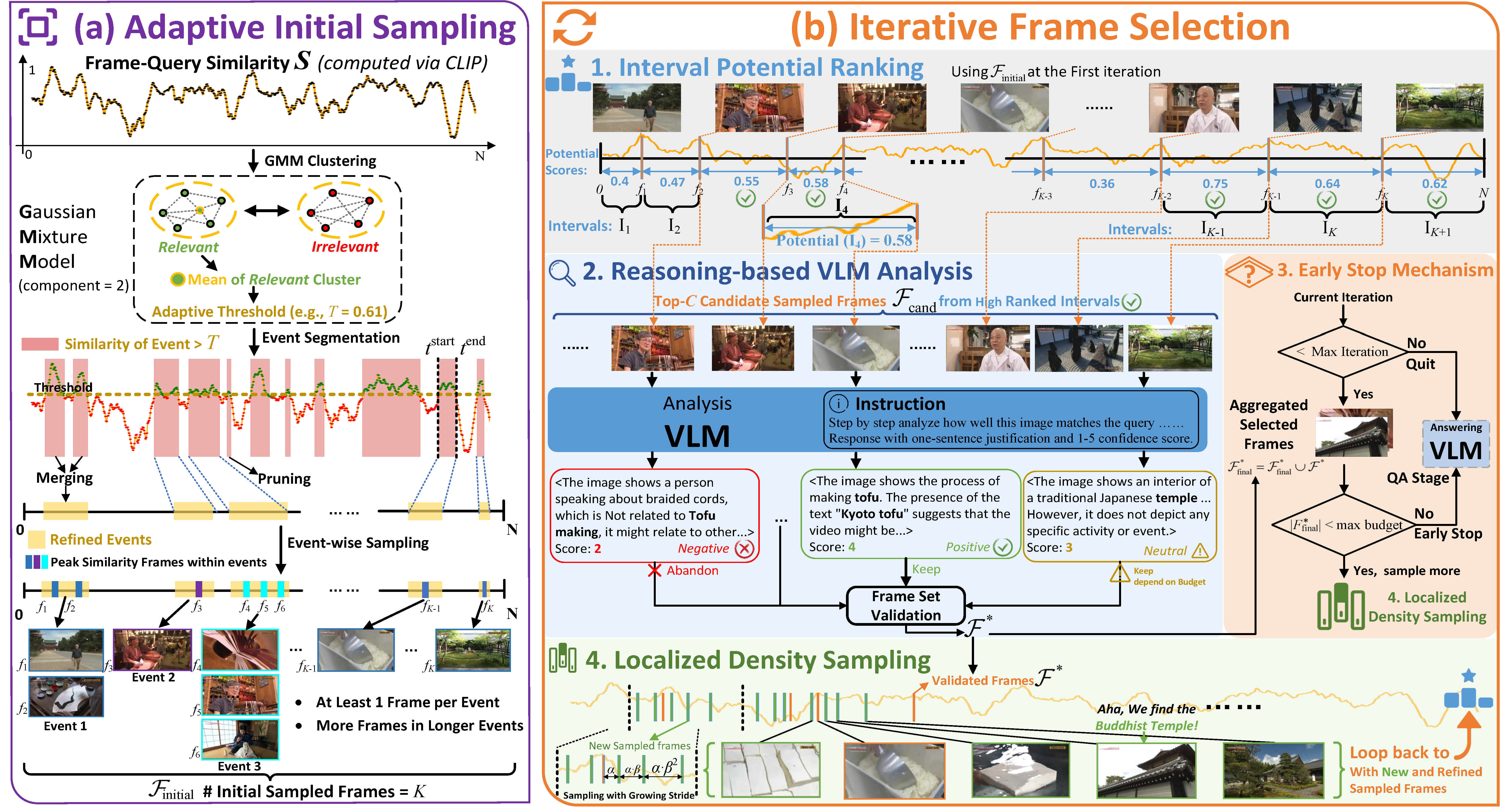
We propose A.I.R., a training-free framework for adaptive frame selection in Video Question Answering that addresses the critical trade-off between lightweight models' poor performance and VLM-based methods' prohibitive computational costs. Our approach achieves state-of-the-art performance on multiple benchmarks (Video-MME, MLVU, LVB, EgoSchema, NextQA) while reducing inference time by ~74% compared to conventional VLM-based analysis.
A.I.R.: Adaptive, Iterative, and Reasoning-based Frame Selection for Video Question Answering
Yuanhao Zou*, Shengji Jin*, Andong Deng, Youpeng Zhao, Jun Wang, Chen Chen (* equal contribution)
Submitted to International Conference on Learning Representations (ICLR) 2026
We propose A.I.R., a training-free framework for adaptive frame selection in Video Question Answering that addresses the critical trade-off between lightweight models' poor performance and VLM-based methods' prohibitive computational costs. Our approach achieves state-of-the-art performance on multiple benchmarks (Video-MME, MLVU, LVB, EgoSchema, NextQA) while reducing inference time by ~74% compared to conventional VLM-based analysis.
2024
HFA-UNet: Hybrid and Full Attention UNet for Thyroid Nodule Segmentation
Yue Li, Yuanhao Zou, Xiangjian He, Qing Xu, Ming Liu, Shengji Jin, Qian Zhang, Maggie M He, Jian Zhang
Knowledge-Based Systems 2025
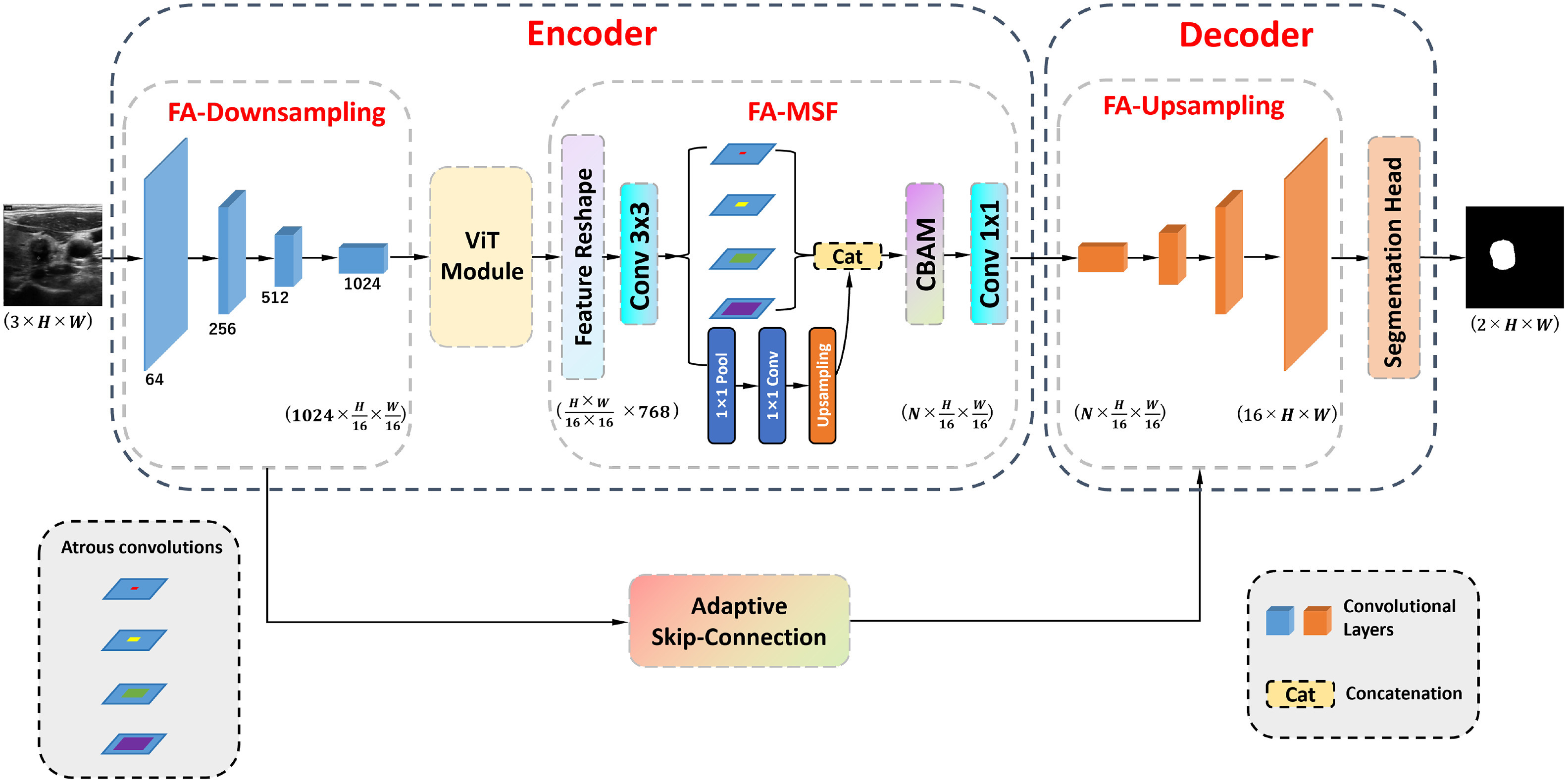
We propose HFA-UNet, a hybrid Transformer-based segmentation model featuring a full-attention multi-scale fusion stage (FA-MSF) that uses atrous convolutions to gather multi-scale context and integrates CBAM to enhance boundary features. Our adaptive skip connection mechanism dynamically adjusts based on input image resolution, achieving state-of-the-art performance across multiple public datasets (DDTI, TN3K, Stanford Cine-Clip) with Dice score improvements up to 2.36% and mIoU up to 4.88%.
HFA-UNet: Hybrid and Full Attention UNet for Thyroid Nodule Segmentation
Yue Li, Yuanhao Zou, Xiangjian He, Qing Xu, Ming Liu, Shengji Jin, Qian Zhang, Maggie M He, Jian Zhang
Knowledge-Based Systems 2025
We propose HFA-UNet, a hybrid Transformer-based segmentation model featuring a full-attention multi-scale fusion stage (FA-MSF) that uses atrous convolutions to gather multi-scale context and integrates CBAM to enhance boundary features. Our adaptive skip connection mechanism dynamically adjusts based on input image resolution, achieving state-of-the-art performance across multiple public datasets (DDTI, TN3K, Stanford Cine-Clip) with Dice score improvements up to 2.36% and mIoU up to 4.88%.
Multimodality Semi-supervised Learning for Ophthalmic Biomarkers Detection
Yanming Chen, Chenxi Niu, Chen Ye, Shengji Jin, Yue Li, Chi Xu, Keyi Liu, Haowei Gao, Jingxi Hu, Yuanhao Zou, Huizhong Zheng, Xiangjian He
International Workshop on Advanced Imaging Technology (IWAIT) 2024
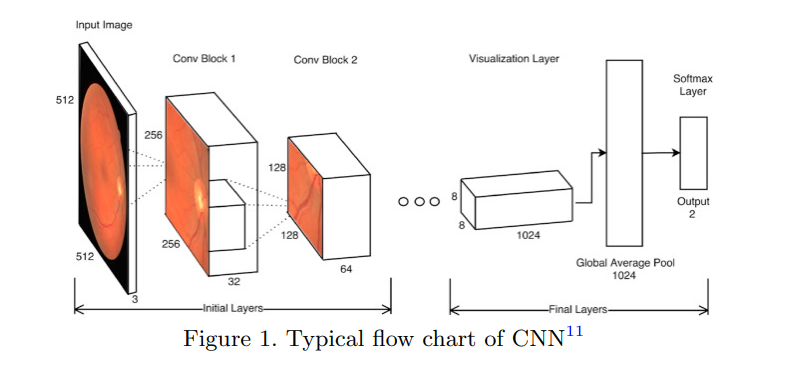
We developed a multi-modal VGG16-MLP architecture that integrates OCT scans and patient clinical labels (BCVA, CST) using guided-loss alignment for knowledge transfer between modalities. Our semi-supervised training approach with pseudo-labeling on the RECOVERY dataset demonstrates improved joint feature learning for ophthalmic biomarker detection.
Multimodality Semi-supervised Learning for Ophthalmic Biomarkers Detection
Yanming Chen, Chenxi Niu, Chen Ye, Shengji Jin, Yue Li, Chi Xu, Keyi Liu, Haowei Gao, Jingxi Hu, Yuanhao Zou, Huizhong Zheng, Xiangjian He
International Workshop on Advanced Imaging Technology (IWAIT) 2024
We developed a multi-modal VGG16-MLP architecture that integrates OCT scans and patient clinical labels (BCVA, CST) using guided-loss alignment for knowledge transfer between modalities. Our semi-supervised training approach with pseudo-labeling on the RECOVERY dataset demonstrates improved joint feature learning for ophthalmic biomarker detection.