
I am a recent MS graduate in Health Informatics from Cornell University (GPA: 4.03/4.30, Academic Excellence) and currently serve as a Research Assistant at UCF's Center for Research in Computer Vision under Dr. Chen Chen. My educational background combines health informatics with computer science and AI from my undergraduate studies at UNNC.
My research focuses on bridging computer vision and healthcare applications, with particular interests in efficient video understanding, medical image segmentation, and multimodal learning. I aim to develop practical AI systems that balance computational efficiency with high performance for real-world deployment in both clinical and general vision tasks.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
 Cornell UniversityMS in Health Informatics
Cornell UniversityMS in Health Informatics
GPA: 4.03/4.30 (Certificate of Academic Excellence)Sep. 2024 - Aug. 2025 -
 University of Nottingham Ningbo ChinaBS in Computer Science with Artificial Intelligence
University of Nottingham Ningbo ChinaBS in Computer Science with Artificial Intelligence
GPA: 3.60/4.00Sep. 2020 - Jun. 2024
Experience
-
 UCF Center for Research in Computer VisionResearch Assistant (Advisor: Dr. Chen Chen)May. 2025 - Present
UCF Center for Research in Computer VisionResearch Assistant (Advisor: Dr. Chen Chen)May. 2025 - Present -
 X_PLORE LabResearch AssistantNov. 2024 - Aug. 2025
X_PLORE LabResearch AssistantNov. 2024 - Aug. 2025 -
 Lecangs Information Technology Co., LtdR&D InternJul. 2023 - Aug. 2023
Lecangs Information Technology Co., LtdR&D InternJul. 2023 - Aug. 2023
Honors & Awards
-
Certificate of Academic Excellence, Cornell UniversityJul. 2025
-
Individual Dream Scholarship of UNNCMay. 2022 & May. 2023
-
6th place in men's double, Zhejiang 16th University Games badminton competitionApr. 2023
-
7th in men's double, Zhejiang University Badminton ChampionshipMay. 2022
Selected Publications (view all )
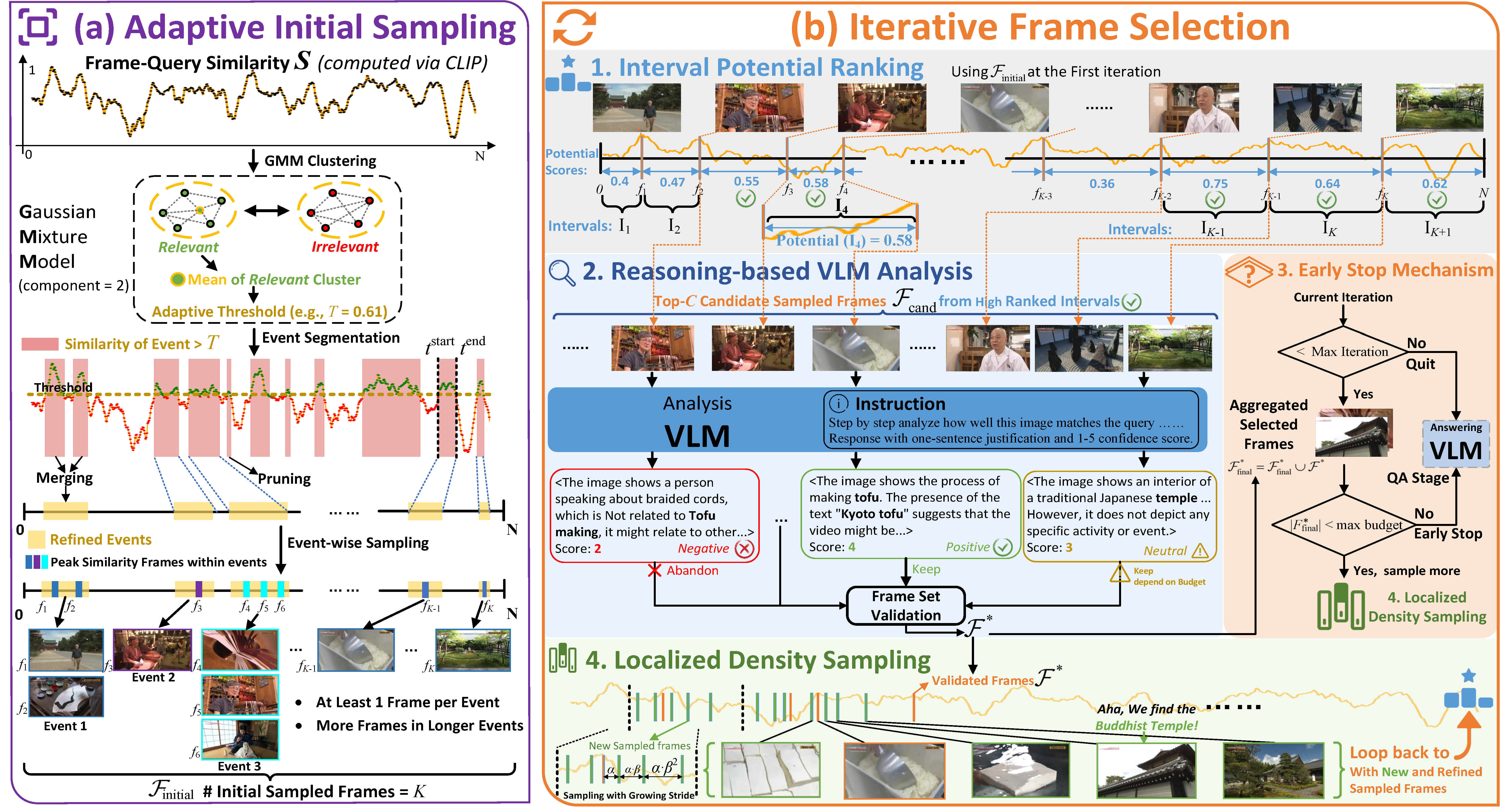
A.I.R.: Adaptive, Iterative, and Reasoning-based Frame Selection for Video Question Answering
Yuanhao Zou*, Shengji Jin*, Andong Deng, Youpeng Zhao, Jun Wang, Chen Chen (* equal contribution)
Submitted to International Conference on Learning Representations (ICLR) 2026
We propose A.I.R., a training-free framework for adaptive frame selection in Video Question Answering that addresses the critical trade-off between lightweight models' poor performance and VLM-based methods' prohibitive computational costs. Our approach achieves state-of-the-art performance on multiple benchmarks (Video-MME, MLVU, LVB, EgoSchema, NextQA) while reducing inference time by ~74% compared to conventional VLM-based analysis.
A.I.R.: Adaptive, Iterative, and Reasoning-based Frame Selection for Video Question Answering
Yuanhao Zou*, Shengji Jin*, Andong Deng, Youpeng Zhao, Jun Wang, Chen Chen (* equal contribution)
Submitted to International Conference on Learning Representations (ICLR) 2026
We propose A.I.R., a training-free framework for adaptive frame selection in Video Question Answering that addresses the critical trade-off between lightweight models' poor performance and VLM-based methods' prohibitive computational costs. Our approach achieves state-of-the-art performance on multiple benchmarks (Video-MME, MLVU, LVB, EgoSchema, NextQA) while reducing inference time by ~74% compared to conventional VLM-based analysis.
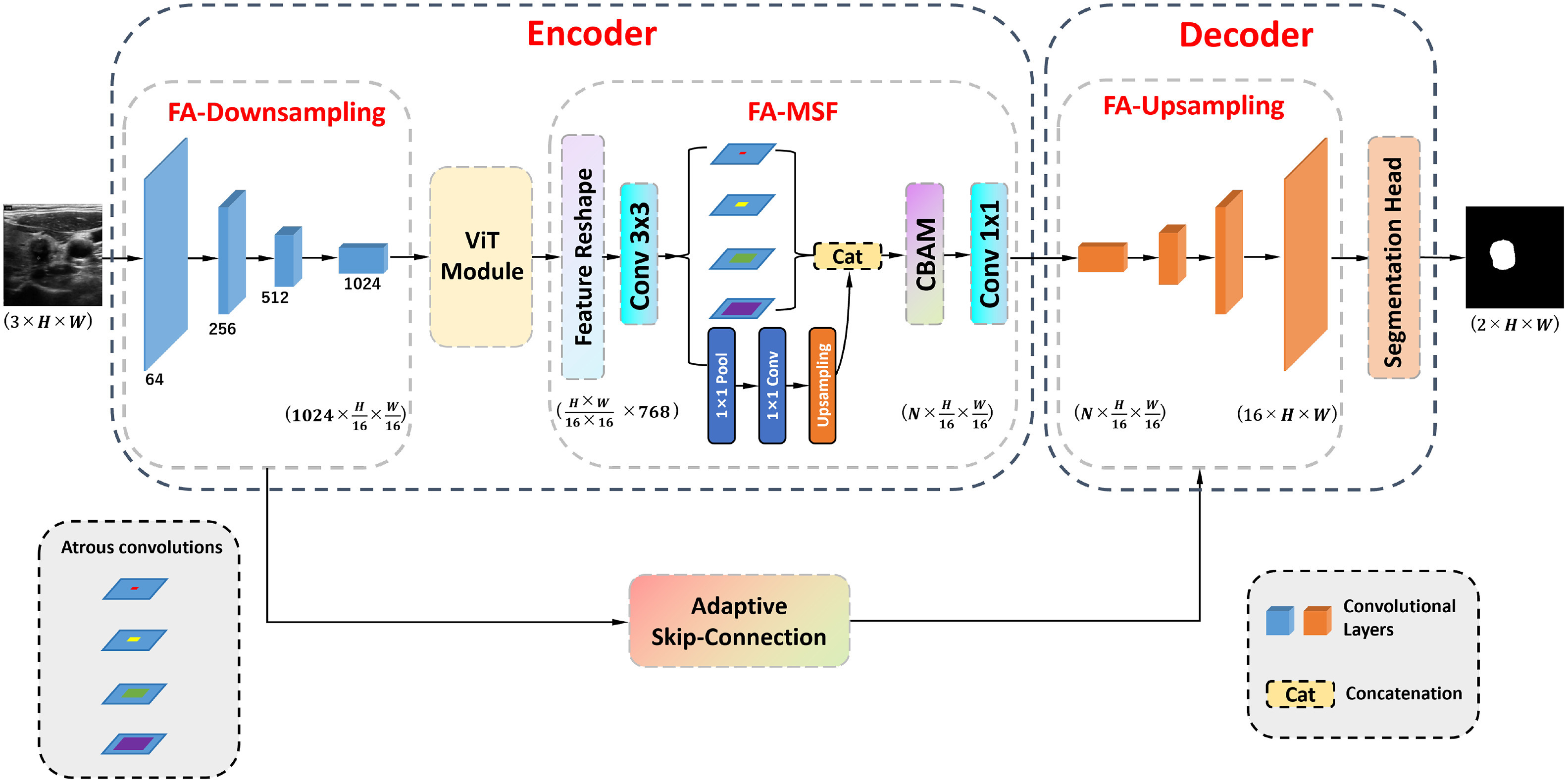
HFA-UNet: Hybrid and Full Attention UNet for Thyroid Nodule Segmentation
Yue Li, Yuanhao Zou, Xiangjian He, Qing Xu, Ming Liu, Shengji Jin, Qian Zhang, Maggie M He, Jian Zhang
Knowledge-Based Systems 2025
We propose HFA-UNet, a hybrid Transformer-based segmentation model featuring a full-attention multi-scale fusion stage (FA-MSF) that uses atrous convolutions to gather multi-scale context and integrates CBAM to enhance boundary features. Our adaptive skip connection mechanism dynamically adjusts based on input image resolution, achieving state-of-the-art performance across multiple public datasets (DDTI, TN3K, Stanford Cine-Clip) with Dice score improvements up to 2.36% and mIoU up to 4.88%.
HFA-UNet: Hybrid and Full Attention UNet for Thyroid Nodule Segmentation
Yue Li, Yuanhao Zou, Xiangjian He, Qing Xu, Ming Liu, Shengji Jin, Qian Zhang, Maggie M He, Jian Zhang
Knowledge-Based Systems 2025
We propose HFA-UNet, a hybrid Transformer-based segmentation model featuring a full-attention multi-scale fusion stage (FA-MSF) that uses atrous convolutions to gather multi-scale context and integrates CBAM to enhance boundary features. Our adaptive skip connection mechanism dynamically adjusts based on input image resolution, achieving state-of-the-art performance across multiple public datasets (DDTI, TN3K, Stanford Cine-Clip) with Dice score improvements up to 2.36% and mIoU up to 4.88%.